„Star Wars“ фанови би требали бити упознати сa златним роботом C-3PО и док се „Star Wars“ можда одвија у далекој галаксији, стварност да машине говоре и одговарају нам на начин сличан људима већ је стварност која постаје све реалнија из дана у дан.

Људи које питате за упите на веб страницама, ваши паметни асистенти, чак и позиви путем интернета, сви имају једну заједничку ствар – ниједан од њих заправо није човек. Сада се можда питате, ако нису људи, како успевају да звуче и изгледају готово индетично као људи? Како тако интелигентно одговарају и како су тако артикулисани? Ово, драги моји, јесте чаролија обраде природног језика.
Шта је NLP (обрада природног језика)?
NLP је комбинација лингвистичких, статистичких и техника машинског учења (Machine Learning) које омогућавају обраду огромних количина података. Ово омогућава рачунарима да схвате нијансе људског језика, разумеју контекст и реагују на њега на смислен начин. Другим речима, NLP алгоритми имају за циљ да премосте људску комуникацију са АI.

Обрада природног језика или NLP односи се на грану вештачке интелигенције која даје машинама способност читања, разумевања и извођења значења из људских језика. NLP комбинује област лингвистике и рачунарске науке како би дешифровао језичку структуру и смернице и створио моделе који могу схватити, анализирати и издвајати значајне информације из текста и говора.
Сваки дан људи међусобно комуницирају путем јавних друштвених медија, размењујући огромне количине слободно доступних података. Ови подаци су изузетно корисни за разумевање људског понашања и навика потрошача. Аналитичари података и стручњаци за машинско учење користе ове податке како би машинама дали способност имитирања људског језичког понашања. Ово помаже у штедњи милиона у смислу радне снаге и времена, јер вам није увек потребна особа са друге стране телефона.
NLP је такође много распрострањенији него што можда схватате – користите га свакодневно у ситуацијама које се чине нормалним и неважним. Не знате како исправно написати реч? Аутокоректор је ту да помогне. Требате да проверите хоће ли ваш чланак или теза бити означени због кршења ауторских права? То је у реду, екстензија за проверу плагијата ће претраживати интернет и пронаћи било које случајеве објављених докумената који се могу подударати с вашим радом стих по стих.
Разлике између NLU-a и NLG-a
Истражујући даље природу NLP-а, треба поменути његове основне циљеве за разумевање и интеракцију са људским језиком. Сходно томе, разликујемо: Разумевање природног језика (NLU), који се бави издвајањем значења и генерацију природног језика (NLG), која се бави производњом људских одговора из података.

NLU помаже да се разумеју замршености и нијансе писаног и говорног језика, бавећи се нејасноћама и контекстуалним варијацијама. На пример, NLU је згодан за разликовање акцента или разумевање сленга.
Користећи статистичке методе и језичке моделе за анализу великих количина података, NLG помаже да се „одговори“ на упите корисника на начин разговора. Такође се бави сажимањем текста, машинским превођењем и креирањем садржаја.

NLP je једноставан за учење
И док се NLP чини заиста „кул“, иновативном и компликованом технолошком концепцијом, заправо је прилично једноставно научити. Почињете сa документом или чланком како бисте алгоритму омогућили разумевање онога што се догађа у њему. Ово није другачије од учења детета читању по први пут.
Почињете извођењем сегментације, што значи разбијање целог документа на његове саставне реченице. То можете постићи сегментацијом чланка дуж интерпункцијских знакова попут тачака и зареза како би алгоритам разумео ове реченице. Затим узимамо речи у реченици и објашњавамо их појединачно нашем алгоритму. Ово се назива токенизација, где сваку реч називамо токеном.
Можемо убрзати процес учења тако да се ослободимо небитних речи које не додају много значења нашем изјави и које су ту само да би наша изјава звучала кохерентније. Ове речи попут „су“ и „the“ (у енглеском језику), називају се стоп речима.
Сада када имамо основни облик нашег документа, требамо га објаснити нашем уређају. Прво почињемо са објашњавањем да неке речи попут „скакање“, „скакање“ и „скакао“ представљају исту реч с додатим префиксима и суфиксима. Ово се назива стемизација.
Такође идентификујемо основне речи за различите облике речи попут времена, расположења, рода итд. Ово се назива лематизација, долази од основне речи леме. Затим објашњавамо концепте именица, глагола, чланова и других делова говора уређају додајући ознаке тим речима. Ово се назива означавање врсте речи.
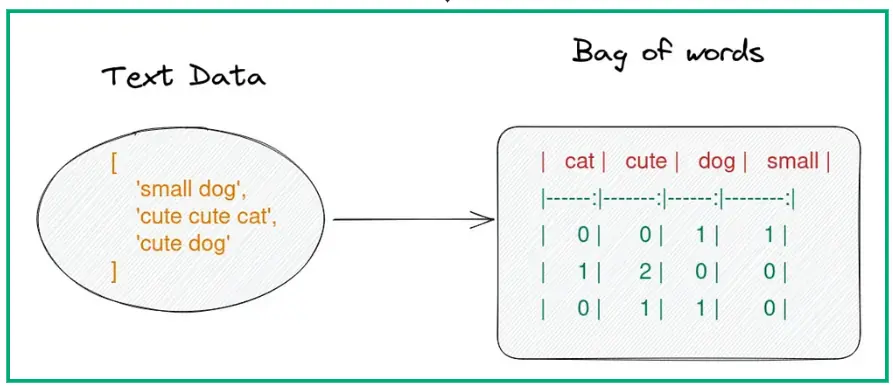
Затим уводимо наш уређај у поп-културне референце и свакодневна имена додајући ознаке имена филмова, важних личности или локација које се могу појавити у документу. Ово се назива означавање именованих ентитета.
Када имамо основне речи и ознаке, користимо алгоритам машинског учења попут Наивног Бејсовог класификатора да научимо наш модел људском сентименту и говору.
На крају дана, већина техника које се користе у NLP-u су једноставне граматичке технике које смо учили у школи.
Будућност људске комуникације са вештачком интелигенцијом
Развој NLP-а отвара нове перспективе за комуникацију између људи и вештачке интелигенције (AI). Кључни трендови обухватају учење пре обуке и трансфер, где напредни модели као што je GPT-4 пружају ефикасне резултате и могућности трансфера знања на различите задатке.
Мултимодални NLP представља идентификацију изазова текста, говора, видеа и слика. Ово се примењује у различитим областима, укључујући видео титлове и аутономна возила, омогућујући прецизнију анализу расположења.
Конверзацијски АI тежи природнијој интеракцији између људи и АI, попут гласовних асистената за паметне куће. Вишејезични NLP такође стреми ка глобалној комуникацији и повећаном приступу информацијама.
Објашњива и поуздана AI постаје кључна, посебно у осетљивим областима као што су здравство и право, како би се изградило поверење и одговорност. Истраживачи такође акцентуjу етичке аспекте NLP-а, фокусирајући се на пристрасност, праведност и решавање етичких проблема, као што је откривање дубоког лажирања.
Концепт NLP-а је револуционисао интеракције човека и машине, тако што је преобликовао начин приступа информацијама и комуникацију. Кроз интеграцију вештачке интелигенције са дубоким учењем (deep learning), рачунари су добили могућност да читају текстове, тумаче говор, анализирају разговоре, одређују осећања и још много тога, доказујући моћ NLP-а у извлачењу вредних увида из података.

Данас видимо бескрајне могућности NLP-а, у распону од четботова и виртуелних асистената до анализе осећања до превода језика. Они су већ трансформисали многе индустрије и побољшали корисничко искуство. Али текућа истраживања и развој у NLP-u обећавају још светлију будућност обележену више напретка и трендова. Ово има потенцијал да комуникацију учини неприметнијом и инклузивнијом него икада раније.